How do databases work?
When you study databases, you wonder why some people always seem to get it right, while the majority just doesn't seem to get it right.
I will tell you in the next 10 minutes how to get it right - or you get your money back.
So, the secret is storytelling. When I think of a database, I think of my friend John who works in front of a big file cabinet like this here:

John's job is to keep his boss happy. His boss comes in every now and then and wants to have some information from the file cabinet, like "how many blue cars have we sold in 2021". Sometimes, the boss also tells John some information that he is supposed to write into the files. This takes a lot of time because every folder has an index that needs to be updated (one index is for "car salesmen", the other for "car types" and many more). Plus, there are "aggregates" (how many cars are still in stock) that need to be updated whenever a car sale goes into the folders. And much more.
Now, John is a very organized guy and he does not want to let his boss wait, so he has a notepad in front of him where he just notes the information that his boss passes to him. Later, when the boss is already gone, he will transfer the information from his notepad to the folders:
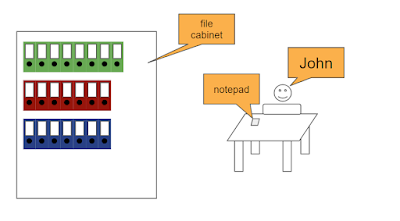
If you now suspect that John is just one of my imaginary friends who represents a server process, go on. The fun is comparing real world with what happens inside a computer.
These folders mostly contain tables about, let's say, car sales. They look like this:
Table: Sales
| Date | Car | Color | Customer | Sales Rep |
|---|---|---|---|---|
| 2022-02-22 | Ford | red | Chester A. Arthur | 25256 |
| 2022-03-23 | Mercedes | black | Abraham Washington | 180777 |
In this table, the "Sales Rep" is a reference to another table, the table of sales representatives. It makes sense to store the name and address of a sales representative only once in a database - you need to change this data only in one place then which avoids inconsistencies. This process of splitting up tables is called normalization. So there will be an additional table
Table: SalesReps
| ID | Name | Address | cars sold |
|---|---|---|---|
| 25256 | Henry Ford | Detroit | 250 |
| 180777 | Albert Einstein | Ulm | 0 |
The ID is a primary key - it uniquely identifies the SalesRep. The "cars sold" field is an aggregate - you could tell it from the table Sales by counting all sales, but it's here for speed reasons.
OK, now we have learned what the data volume is - it is the file cabinet, and what the log volume is - it's the notepad. John is the log writer and he talks with his boss in a language called SQL (structured query language). In reality, the boss is of course the user who runs an application which passes SQL commands to the database.
Now, John has to make sure the data is absolutely durable - if he dies, there will be a successor who will take over notepad and the file cabinet just from the point where John left. In IT this means, you have to put your log volume onto disk. Not into RAM where it would not survive a reboot.
Now one important question is, from when on does the durability of the data need to be guaranteed. The answer is: As soon as John allows his boss to go back to his work. In SQL, this is equivalent to when the commit returns. This has a bit lost its meaning as most databases provide and auto-commit. If you issue a writing command in SQL, once the command says "finished" or so, data is guaranteed to be persisted.
Also, referential integrity must be guaranteed: The sales rep referred to in the table sales must be in the table SalesReps. If you delete a sales rep, there must not be any sales in the sales table referencing to him. This is just another job a database has to do.
The notepad is getting thicker and thicker on John's desk. So a periodic cleanup is needed where John gets free time to store everything from his notebook into the folders. Afterwards, the notepad can be freed. That's called a savepoint. It typically happens all 5 minutes in a database.
John is the logwriter and he has a friend the dbwriter who always reads John's notepad and transcribes it into the file cabinet.
From time to time the boss orders a bunch of students to copy all folders. Of course this can lead to inconsistencies if the dbwriter is just writing to it. So the boss first tells everybody in the office to keep the folders consistent. This is slowing down the whole business, but needed so the students can copy the file cabinet. It's called the backup mode. Compare it with a permanent savepoint.
So far I have only talked about OLTP ACID databases.
Let's look at ACID first. You may have seen that we keep every transaction
* atomic - every command must be executed completely of not at all. There will be no point in time when the car has already been inserted into the car sales table, but not the color.
* consistent - you cannot insert a car sales if the salesperson ("foreign key") does not exist.
* isolated - no matter if you do one operation at all or several at the same time, the operation will always work the same
* durable - once the logwriter gives the okay, the data will be there and stay there until it is deleted
This is very expensive and makes scaling very hard. Main challenge is that if your business grows, you must be able to grow database performance quickly. It is easy to do this if you can run one database on several computers. Then you just add computers in order to scale. Let's imagine we have not one, but 10 computers all inserting data into the table car sales. For every insert operation they'd have to look up the table salesreps, if the salesrep has been fired meanwhile. Now, this forms the next bottleneck - there can be only one computer holding the latest authoritative information on salesreps. And if this one computer gets overrun by queries, we have resolved one bottleneck, but opened another one.
So, if you are willing to give up the consistency requirement, you can scale much better and - as an effect - have much more performance. This is what non-ACID databases are for which for the biggest part overlap with the term NOSQL databases.
And now that you have given up the consistency paradigm, you can basically think of a database as a giant key-value store.
Of course this will not help you with your car sales application, neither with financial applications or any enterprise application that you can show to tax auditor.
But if you are programming a game and just want to have one table for user data, it's fine to use NOSQL. The key-value store could look like this:
| user | highscore |
|---|---|
| John | 25256 |
| Jack | 180777 |
| BlackAnt | 311080 |
oh, and then, you may discover that you also want to store more information. Another column for when the user registered. Typically, with ACID databases, you will do this by adding another column to the database and rewriting your application. With NOSQL databases, however, it is not untypical to leave it with one column and just add the new information as a json field.



Comments
Post a Comment